개요
논문이 나온 연도가 2018년이기 때문에 그에 맞춰서 글을 읽어야 한다.
기존의 CNN 네트워크가 지역적으로 가까운 픽셀들과의 연산이기 때문에 먼 거리의 픽셀들과의 종속성은 계산되지 않는다는 점을 개선할 수 있는 방법이다. 논문 내 Reference [4] (A. Buades, B. Coll, and J.-M. Morel. A non-local algorithm for image denoising. In Computer Vision and Pattern Recognition (CVPR), 2005.) 에서 연산방법의 영감을 받았다고 한다.
제안하는 방법의 장점은 (논문에서 써있는 대로)
1. 많은 컴퓨터 비전 작업에 연결해서 사용할 수 있다. (가변적인 입력크기에 대해 유연하게 적용가능하다)
2. Kinetics, Charades 데이터셋에서 좋은 성능을 보여주었다. (Video Classification)
3. 장거리 픽셀에 대한 종속성을 캡처할 수 있다.
4. 더 적은 레이어 수로 좋은 성능을 얻을 수 있다. 3D convolution 보다 경제적이다.
기존의 연구에서 먼 거리의 픽셀과의 연관성은 깊은 계층을 거친 후에 나오는 feature map 에 의해 계산가능 했다.
제안 방법
우선 일반적인 non-local operation 을 다음과 같이 정의한다.
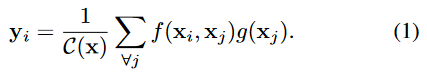
식을 설명부분을 요약하면 $x_i$ 에 대해서 가능한 모든 $x_j$ 와 관계를 계산하는 함수 $f$의 출력과 $x_j$ 의 representation 을 계산하는 함수 $g$의 출력을 곱하고 계수 $C(x)$로 정규화한다는 내용이다.
이것은 fully connected layer와도 다른점을 소개하는데, 그 이유는 fc는 서로 다른 위치간의 관계를 계산하는 것이 아니라 학습된 가중치로 연산을 수행한다는 것과 고정된 입력과 출력크기를 가지고 있다고 설명한다.
설명을 단순하게 하기 위해 논문에서 함수 g는 1*1 혹은 1*1*1 convolution 연산으로 가정한다고 한다.
함수 f로 사용할 수 있는 함수의 예시

dot-product similarity를 계산하는 방식으로 이를 사용한 이유는 구현하기 쉽기 때문이었다고 설명했다. 정규화 계수는 다음과 같이 설정했다.

그 외에도 다양한 함수 f의 instantiations 가 소개된다.
non-local block의 연산은 다음과 같이 계산된다.

$y_i$ 는 eq 1에서 주어진 식에서 계산하고 $+x_i$ 는 residual connection 을 나타낸다고 설명한다. 블록 구조의 예시는 그림 2에 나와있다 (아래).

행렬을 통해 계산할 수 있다고 설명하며, 더 효율적으로 만들 수 있는 방법을 추가로 설명한다.
공식 소스코드는 caffe로 되어있다. non-local block 이 정확히 어떻게 구현되어있는지 model에 해당하는 소스코드가 레퍼지토리에서 보이지 않으니 다른 구현체를 참고하며 공부를 이어나가면 될 것 같다.
참고자료
github : https://github.com/facebookresearch/video-nonlocal-net
GitHub - facebookresearch/video-nonlocal-net: Non-local Neural Networks for Video Classification
Non-local Neural Networks for Video Classification - GitHub - facebookresearch/video-nonlocal-net: Non-local Neural Networks for Video Classification
github.com
https://paperswithcode.com/paper/non-local-neural-networks
Papers with Code - Non-local Neural Networks
#8 best model for Action Classification on Toyota Smarthome dataset (CS metric)
paperswithcode.com
Kinetics dataset : https://www.deepmind.com/open-source/kinetics
Kinetics
A collection of large-scale, high-quality datasets of URL links of up to 650,000 video clips that cover 400/600/700 human action classes, depending on the dataset version. The videos include human-object interactions such as playing instruments, as well as
www.deepmind.com
Charades dataset : http://vuchallenge.org/charades.html
Charades Challenge
Charades Challenge Recognize and locate activities taking place in a video Introduction --> The Charades Activity Challenge aims towards automatic understanding of daily activities, by providing realistic videos of people doing everyday activities. The Cha
vuchallenge.org
15-01 어텐션 메커니즘 (Attention Mechanism)
앞서 배운 seq2seq 모델은 **인코더**에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, **디코더**는 이 컨텍스트 벡터를 통해서 출력 …
wikidocs.net
An introduction to Attention
The why and the what
towardsdatascience.com
https://ys-cs17.tistory.com/46
CNN attention based networks
현재 딥러닝을 주도하고 있는 분야는 자연어 처리 분야 및 컴퓨터 비전 분야입니다. 보통 자연어 처리는 RNN, LSTM 등을 기반으로 모델이 형성되고, 컴퓨터 비전은 CNN 기반으로 모델이 형성이 됩니
ys-cs17.tistory.com
'컴퓨터과학' 카테고리의 다른 글
| apple silicon 칩 컴퓨터에서 vmware 로 kubuntu 설치하기 (0) | 2023.05.04 |
|---|---|
| [논문읽기] Fibro-CoSANet: Pulmonary Fibrosis Prognosis Prediction using a Convolutional Self Attention Network (0) | 2023.05.03 |
| [논문읽기] Segment Anything (0) | 2023.05.03 |
| [논문 읽기] Vanilla GAN (0) | 2023.05.01 |
| [study] 감마보정 (Gamma Correction, Gamma Encoding) (0) | 2023.05.01 |




댓글