1. 개요 및 연구동기
네트워크 훈련을 위해 레이블이 지정된 소수의 이미지와 레이블이 지정되지 않은 다수의 이미지를 활용하는 것을 목표로 하는 SSL(반지도 학습)은 의료 영상 분할에서 데이터 주석 부담을 완화하는 데 유용합니다. 의료 영상 전문가의 경험에 따르면 질감, 광택, 매끄러움과 같은 국부적 속성은 의료 영상에서 병변, 폴립과 같은 대상 물체를 식별하는 데 매우 중요한 요소입니다. 이에 동기를 부여하여 우리는 반지도 의료 영상 분할에서 로컬 특징에 대한 표현 능력을 향상시키기 위한 교차 수준 대조 학습 방식을 제안합니다. 기존의 이미지별, 패치별 및 포인트별 대조 학습 알고리즘과 비교하여 우리가 고안한 방법은 보다 복잡한 유사성 단서, 즉 전역 및 로컬 패치별 표현 간의 관계 특성을 탐색할 수 있습니다. 또한 교차 레벨 의미 관계를 완전히 활용하기 위해 패치 예측을 전체 이미지 예측과 비교하는 새로운 일관성 제약 조건을 고안했습니다. 교차 수준 대조 학습 및 일관성 제약의 도움으로 라벨이 지정되지 않은 데이터를 효과적으로 탐색하여 폴립 및 피부 병변 분할에 대한 두 개의 의료 이미지 데이터 세트에 대한 분할 성능을 각각 향상시킬 수 있습니다. 우리의 접근 방식에 대한 코드는 여기에서 확인할 수 있습니다.
CNN 을 기반으로한 모델의 최적화에는 데이터가 많이 필요하다. 준지도 학습은 주석 작업량을 줄이는 데 도움이 될 수 있습니다. 이 항목에서는 분할 모델이 주석이 달린 희소한 데이터로 과적합되는 것을 방지하려면 레이블이 지정되지 않은 데이터를 합리적으로 탐색하는 것이 중요합니다.
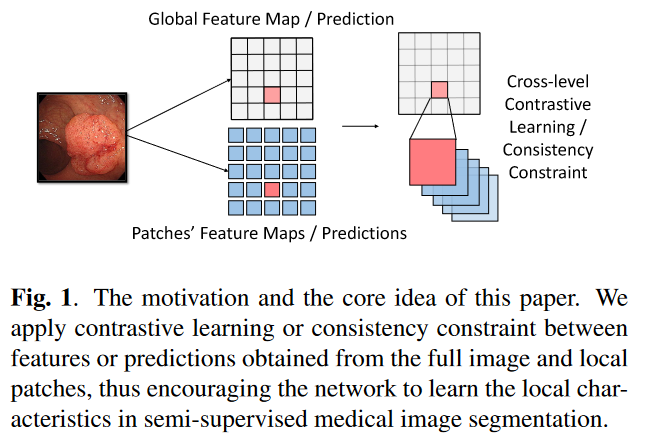
레이블이 지정되지 않은 이미지를 포함하는 방법들은 의사레이블을 자동으로 할당하려고 한다. 이러한 종류의 방법들의 성능은 의사라벨의 품질에 따라 달라진다. 게다가 자체 라벨링 전략은 잘못된 예측을 수정하기 어렵기 때문에 편향의 영향을 심하게 받을 수 있다. 레이블이 지정되지 않은 이미지를 활용하는 또 다른 일반적인 작업은 upstream pretext 작업을 통해 레이블이 지정되지 않은 데이터를 효과적으로 시각적으로 표현하는 자기지도 학습이다.
대조학습 알고리즘은 일반적으로 유사한 이미지 쌍을 긍정적인 인스턴스로 간주하고 서로 다른 이미지 쌍을 부정적인 인스턴스로 간주한다. 훈련 중에 긍정적인 인스턴스는 서로 더 가까워지도록 권장하는 방면 부정적인 인스턴스는 상호 배타적으로 제한된다. 이미지 분류 작업에서 대부분의 CL 접근 방식은 이미지 수준 임베딩에 대조 메트릭 학습 제약 조건을 적용하여 SimCLR[5] 와 같은 파이프라인을 따른다. 그러나 이미지 분할과 같은 경우에는 CL접근을 하면 공간관계정보를 무시하게 된다.
의료 영상 분석에서 질감, 매끄러움 등의 국소적 특징은 polyp, 종양, 장기 등 대상 물체를 식별하는 데 중요한 요소이다. 이러한 기능은 순방향 전파가 CNN 모델의 더 깊은 계층에 도달함에 따라 점차적으로 희석된다. 이러한 로컬 특징에 대한 표현능력을 강화하는 것을 목표로 하는 cross-level contrastive learning scheme을 제안한다. 이미지가 제공되면 UNet을 사용하여 feature map을 생성하고 dense predictions을 도출한다.

3. Experiments
우리는 두 가지 의료 세분화 데이터 세트에 대해 제안된 준 지도 학습 접근 방식을 평가한다. UAMT, URPC 를 포함한 기존의 최첨단 방법과 비교한다.
3.1 Datasets
Kvasir-SEG dataset[12] : 픽셀 수준 수동 레이블이 있는 1,000개의 백색광 대장내시경 이미지가 포함된 폴립 분할 데이터세트입니다. 60% 이미지를 훈련 세트로, 20% 이미지를 검증 세트로, 나머지 20% 이미지를 테스트 세트로 무작위로 선택합니다. 훈련 세트 중에서 20%(120)개의 이미지를 레이블이 있는 데이터로 선택하고 나머지 80%(480)를 레이블이 없는 데이터로 선택합니다.
ISIC 2018 dataset[13] : 피부 병변 분할 데이터세트입니다. 우리는 픽셀 수준의 병변 라벨이 있는 2594개의 피부 이미지를 사용합니다. 60% 이미지를 훈련 세트로, 20% 이미지를 검증 세트로, 나머지 20% 이미지를 테스트 세트로 무작위로 선택합니다. 훈련 세트 중에서 10%(156)개의 이미지를 레이블이 지정된 데이터로 선택하고 나머지 90%(1400)를 레이블이 없는 데이터로 선택합니다.
3.2 Implementation Details and Evaluation Metric
우리의 접근방식은 Pytorch 로 구현되었고 A100 을 사용했다. 네트워크는 기본 매개변수 설정과 함께 Adamw [16] 최적화 프로그램을 사용하여 훈련되었습니다. 모든 훈련 미니 배치는 주석이 달린 이미지 4개와 주석이 없는 이미지 4개로 구성됩니다. 모든 이미지는 320*320 크기로 조정되었습니다. 공정한 비교를 위해 모든 방법에 동일한 백본 모델, 지도 학습 손실, 데이터 세트 분할 및 에포크가 사용되었습니다. 우리는 평균 절대 오차(MAE), 평균 교차점(mIoU) 및 전경의 주사위 계수를 사용하여 각 방법의 성능을 평가합니다. 각 실험마다 라벨이 붙은 이미지를 무작위로 3번 선택하고 평균과 표준편차를 보고합니다.
3.3 Results
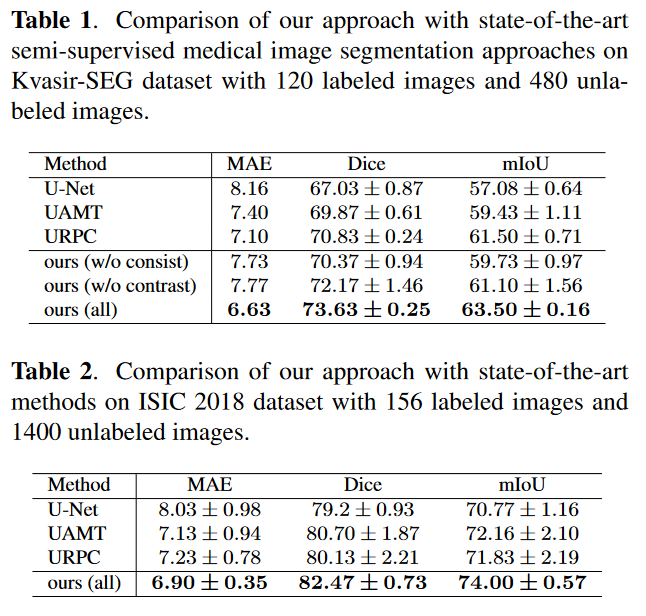
표 1은 Kvasir-SEG 데이터 세트에 대한 준지도 분할 알고리즘의 결과를 보여줍니다. 기준선 및 기타 기존 SOTA 방법과 비교하여 우리의 접근 방식은 중요하고 일관된 개선을 달성합니다. 또한, 모순적 손실 없이 일관성 손실만 사용하거나, 일관성 손실 없이 모순적 손실을 사용하는 경우 모든 평가 지표는 향상되지만 안정적이지는 않습니다. 절제 실험의 결과는 우리가 제안한 두 가지 손실 함수 모두 네트워크 성능을 크게 향상시킬 수 있음을 보여줍니다. 표 2는 ISIC 2018 데이터 세트의 결과를 보여줍니다. 우리의 접근 방식은 ISIC 2018 데이터세트에서도 일관된 효율성을 보여줍니다.
3.4 Visualization
그림 3은 분할결과를 보여준다. 기존의 방법들은 배경이 단순하고 눈에 띄는 물체가 있는 경우에도 효과적으로 이미지를 처리할 수 있다는 결론을 이미지로부터 얻을 수 있다. 그러나 이러한 방법들은 물체와 배경이 유사할 때 모든 폴립이나 피부 병변 영역을 완전히 분할할 수 없고, 배경이 눈에 띄는 경우 모든 배경 영역을 억제할 수 없다. 어수선하다. 대조적으로, 우리의 접근 방식은 복잡한 경우에도 배경에서 객체 영역을 강력하게 더 잘 분할할 수 있습니다.

4. Conclusion
본 연구에서는 의료 영상 데이터에 라벨을 붙이는 인간의 작업량을 줄이기 위해 semi-supervised 의료영상분할 문제를 조사했다. 우리 프레임워크는 이미지 내 여러 수준에 걸쳐 본질적인 관계를 탐색하여 레이블이 지정되지 않은 데이터를 사용할 수 있습니다. 두 가지 공공 의료 데이터 세트에 대한 광범위한 실험을 통해 우리의 접근 방식이 최첨단 준지도 학습 방법보다 일관되게 우수한 것으로 나타났습니다.




댓글